Database Schema
The Collect! Database Schema contains all the information
that you can access through your ODBC interface. This
information is stored in tables. There is a separate table in the
database schema for each type of record.
 You can examine the database schema directly if you
are using Version 11.3 Build 1.1 or newer. Please refer to the
Help topic, CV11 Admin Tool for more information.
You can examine the database schema directly if you
are using Version 11.3 Build 1.1 or newer. Please refer to the
Help topic, CV11 Admin Tool for more information.
You can see the list of these tables when you access Collect!
through an ODBC interface such as MS Access.
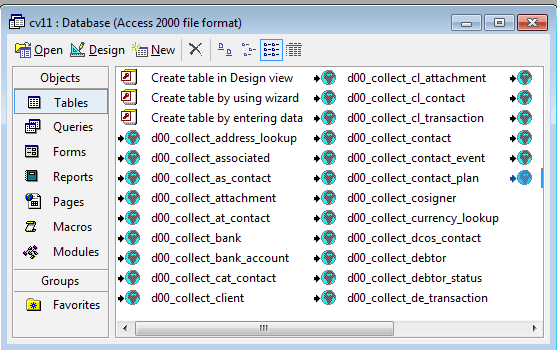
Database Tables viewed through an ODBC connection
In the example above, each table is prefaced by the short
code that Collect! uses to identify each of its three databases.
The prefix d01_collect indicates that we are
viewing the database structure of the DEMODB database.
The working, or MASTERDB, database is prefaced
by d00_collect and the prospecting, or PROSDB,
database is prefaced by d02_collect.
There is also an archive database for each of these databases,
the prefixes are a00_collect,a01_collect
and a02_collect, respectively.
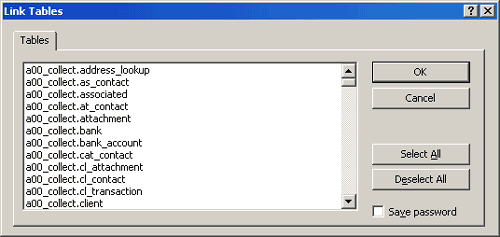
Tables in the a00_collect Archive Database
 WARNING: The Archive databases are Read Only through
the Collect! interface. They are intended for storing unused
records. In the ODBC interface, these databases are not
Read Only. However, the Archive database tables, which
start with prefixes a00_collect, a01_collect and a02_collect,
should NOT be written to or edited through ODBC!!
WARNING: The Archive databases are Read Only through
the Collect! interface. They are intended for storing unused
records. In the ODBC interface, these databases are not
Read Only. However, the Archive database tables, which
start with prefixes a00_collect, a01_collect and a02_collect,
should NOT be written to or edited through ODBC!!
When you drill down into each table in MS Access, you see the
list of fields that each table holds. These fields are prefaced with
a short code that identifies the table.
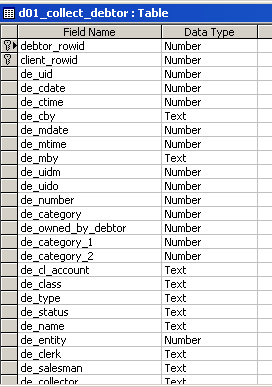
Debtor Fields in the d01_collect_debtor table
In the example above, the prefix de_ indicates
the Debtor record.
 Rowid fields are primary key fields used to
link the information in different tables. In the example above
there are two of these right at the top of the list, the
debtor_rowid and client_rowid.
Rowid fields are primary key fields used to
link the information in different tables. In the example above
there are two of these right at the top of the list, the
debtor_rowid and client_rowid.
In the tables, you see the actual name of the field in the
database. This is the name you use to access the field
through your ODBC interface., e.g. de_name will retrieve
information in the Debtor Name field.
Primary keys are used to relate information between
tables. These fields are not part of the Collect! user interface.
They are only found in the Database Schema. You can
recognize them by the suffix rowid in the
field name.
Key fields are indexed fields in the database. Searching
and sorting by these fields is quick. Queries should always
be based on a key field. This is especially important for
complicated queries returning large data sets.
Querying on optional keys may not return the
data you expect if the field contains no data. Try to query
on a key field instead. Please see
How To Filter Data With The Where Clause for more
information about optional keys.
See Also
- ODBC Topics

|
Was this page helpful? Do you have any comments on this document? Can we make it better? If so how may we improve this page.
Please click this link to send us your comments: helpinfo@collect.org