File Format Specification
This form allows you to define the specifics of your import/export
routine - what and how you want to import or export. When setting
up importing or exporting, you specify the type of file layout
(fixed length, comma separated or other) and what records are
contained in the file.
Click into the Import Record Definition list to add and modify the
records and fields you want to import or export.
 To access the File Format Specification form, if you are
not already viewing it, select File from the top menu bar and then
select Import/Export, then choose Customize Import/Export,
Edit File Format. Or, choose Edit Format from the Import menu
or the Export menu.
To access the File Format Specification form, if you are
not already viewing it, select File from the top menu bar and then
select Import/Export, then choose Customize Import/Export,
Edit File Format. Or, choose Edit Format from the Import menu
or the Export menu.
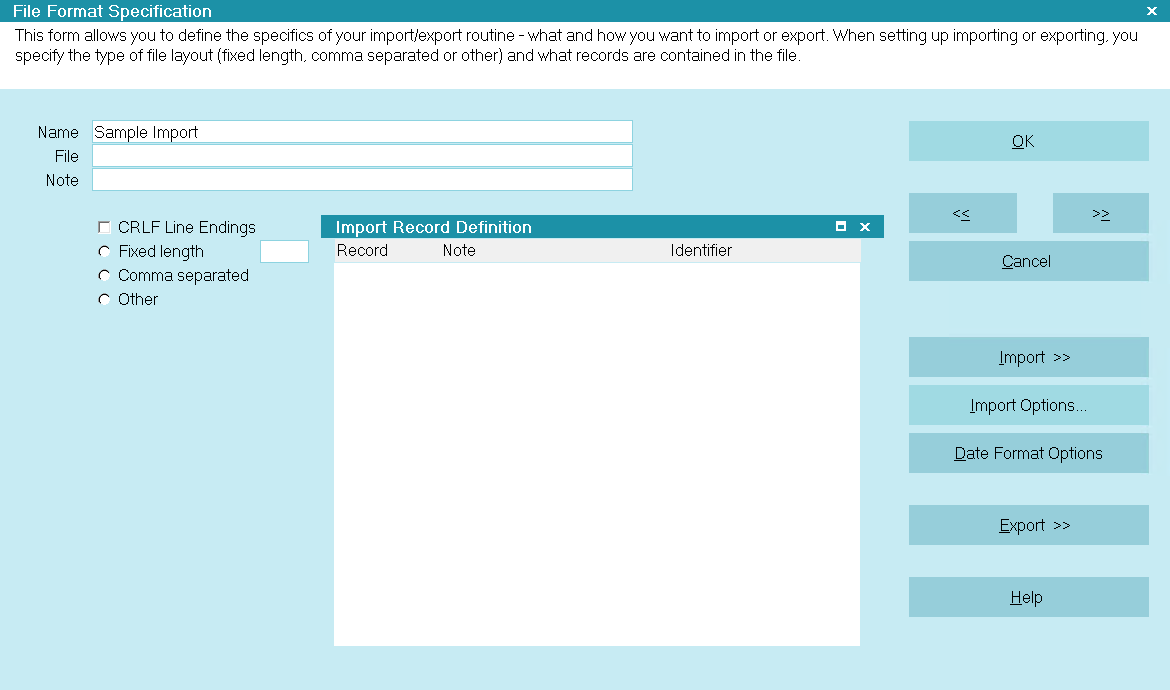
File Format Specification
You can choose whether the file is fixed length or comma
separated (CSV) ASCII. You are also given additional options
for London Bridge EDI format, which is essentially a fixed length
file with a header record for verification purposes.
When importing, you can choose the records and fields to import
and set a number of options. These options include whether you
want the system to automatically schedule a letter and a review
contact, or calculate interest automatically.
When exporting, you can specify which fields you want to export.
Fixed length files are padded with spaces if you leave blank spaces
in a line of data.
Do not modify the file format samples until you are
thoroughly familiar with the concepts of files and file
transfers. Both sending and receiving import programs
must have identical format specifications to function
correctly.
Name
This is a name for the import specification. Be sure to use
a name that will jog your memory. You will notice that the
sample file formats have names describing their function.

File
This is the name and path of the file to be imported. You
cannot use wild-card characters. Import by default expects
the files to be located in the Collect! executable directory,
that is, Collect\bin. If you know that the name of the file will
always be the same, you can enter the exact filename.
Otherwise, leave this blank.
 You can use today's date in the file extension.
If you enter "filename.@d", the system will
create a file extension using today's date
formed as filename MMDDYY.
You can use today's date in the file extension.
If you enter "filename.@d", the system will
create a file extension using today's date
formed as filename MMDDYY.
Note
Enter a description for this import specification if there is
more than one file format you work with regularly. This is
a free form textual area for your use.
Crlf Line Endings
The import modules uses Line Feeds (LF) by default to determine
the end of a line. If you file has a mixture of Line Feeds and
Carriage Returns (CRLF), then you can select this option to
tell Collect! to use Carriage Returns as the line endings.
If Collect! encounters a Line Feed, it will replace
the line feed with a space.
Fixed Length
This specifies one of two basic file formats. In this case,
all information is formatted with either valid data or spaces.
See the section, FIXED LENGTH DEFINED, below.
When you select a fixed length file, you are implying a
number of things. For example, each field in a fixed length
file has an OFFSET and a LENGTH. Some of the options
in the record import definitions and field import definitions
directly control how information is written to fixed length files.
Line Width
You can optionally enter the actual width of each line.
Normally fixed length files have each line separated with
a carriage return (CR) or line feed (LF) character, but in
some odd cases there may be other separators. In this
case, the import may not work until you specifically tell
it the actual width of each line of the file being imported.
Line Width is used on both importing and exporting.
On exporting fixed length records, the line width is used
to pad partially filled lines.
On importing, the line width forces the read operation
to read the specified number of characters, rather than
freely reading up to the end of the next line.
If you import from a fixed length file and the import doesn't
seem to be working, you might need to define the actual
line width.
Fixed Length Defined
This is one of two major field format conventions. Fixed Length
fields are filled with spaces to a specified width. Each field has
an offset from the start of the line, and a length in number of
characters.
Imagine one line of the Fixed Length import file looks like this:
| SMITH, FRED | 10004A 10000.00 199 ESTELLINE RD. |
| 123456789012345678901234 | 567890123456789012345678901234567890 |
The start of the Name field is at position 1 and the length
is 24. The Number field starts at position 25 and its length
is 6.
Notice how the name starts at character position 1, and there
is room for a long name, although not all of the space is used
with this one. The length of the name field is 24 characters.
Then the account number starts at character position 25 in
the file, and is 6 characters wide.
When you import Fixed Length files, you will need to know the
starting position and width of every field you want to import.
This information is typically available from the person who
created the file.
Comma Separated
Comma separated files place quotes around text fields
and separate fields with commas. These files are simpler
to work with compared to fixed length files, as only the
field order needs to be known.
Comma Separated Defined
The data used in the fixed length file example above looks
like this in a CSV format.
| "SMITH,FRED","10004A",10000.00,"199 ESTELLINE RD." |
Notice that numeric fields don't have quotes. Import can accept
numerics with or without quotation marks.
Notice the commas separating the fields.
Notice the quotation marks around fields.
Text fields are surrounded by quotation marks, and fields are
separated with commas. Also notice that blank space is eliminated,
making this a more space-efficient way of transferring information.
Column Count In CSV Imports
The field/column count is not retained across records. In reality,
the count is restarted on each New record definition.
Other
In some cases, files do not conform to fixed length or
comma separated standards. For example, X12 EDI files
often use [~] and [^] as field and record delimiters. In
other words, some files are neither fixed length nor
comma separated, and the Collect! import/export functions
can still work correctly.
When you specify the OTHER file format, spaces are
displayed to enter field and record delimiters.
Field Delimiter
Enter a character that is placed between fields in the file
being processed.
For example, when we created an import/export specification
for an X12 EDI file we entered [ ~ ] as the field separator.
You can also enter hex codes in these locations to
allow you to work with any characters. Hex codes are
specified by entering xNN where the NN is a two digit
number. For example, when we entered x0Dx0A, the
system exported a carriage return and line feed.
Please refer to the sections below, TAB
DELIMITERS and PIPE DELIMITERS, for
more information.
Collect! can read multiple HEX and character codes in a
single pass. Please refer to Help topic,
Multi Character Field Delimiters for details.
Tab Delimiters
When TABS are used to separate fields in your file to be
imported, there is a special hex code to indicate this. It
is x09. This is entered into the Field
Delimiter Field so that Collect! can determine field
separations.
In your File Format Specification, choose OTHER and the
Record Delimiter and Field Delimiter fields will become visible.
Type in the following values.
Field delimiter: x09
Record delimiter: x0Dx0A
This would be a tab separating the fields and a carriage return
and line feed separating the records. x09 is
the code for the TAB character.
In your file, it might look like:
>>
A line of text in the file might look like:
120035>>3000>>56745>>etc.
This might indicate a Principal Amount of $1200.35 at 30%
commission with $567.45 still owing.
Pipe Delimiters
When PIPES are used to separate fields in your file to be
imported, there is a special hex code to indicate this. It
is x7C. This is entered into the Field
Delimiter Field so that Collect! can determine field
separations.
In your File Format Specification, choose OTHER and the
Record Delimiter and Field Delimiter fields will become visible.
Type in the following values.
Field delimiter x7C
Record delimiter x0Dx0A
This would be a pipe separating the fields and a carriage return
and line feed separating the records. x7C is
the code for the PIPE character.
In your file, it might look like:
|
A line of text in the file might look like:
120035|3000|56745|etc.
This might indicate a Principal Amount of $1200.35 at 30%
commission with $567.45 still owing.
Record Delimiter
Enter a character that is placed after each record in the file
being processed.
For example, when we created an import/export specification
for an X12 EDI file, we entered [ ^ ] as the record separator.
You can also enter hex codes in these locations to allow
you to work with any characters. Hex codes are specified
by entering xNN where the NN is a two digit number. For
example, when we entered x0Dx0A, the system exported a
carriage return and line feed.
Please refer to sections above, TAB DELIMITERS
and PIPE DELIMITERS for more information.
Collect! can read multiple HEX and character codes in a
single pass. Please refer to Help topic,
Multi Character Field Delimiters for details.
Multi Character Field Delimiters
You can specify multiple field delimiters in Collect!'s
Import/Export for both Field Delimiter and Record
Delimiter fields. You can specify multiple HEX codes and/or
multiple ASCII codes simultaneously. This lets Collect!
parse more complex data files where different
delimiters are used to separate various data items.
When importing data, every Delimiter in the field will be
interpreted as a Record or Field Delimiter in the incoming
data, unless the first two delimiters are x0Dx0A,
in which case the first two will be used together as a whole.
When exporting data, only the first delimiter specified in
the Delimiter field will be used, unless the first two
delimiters are x0Dx0A, in which case
the first two will be used together as a whole.
Hex Code Table
For your convenience, the following table will help you
when specifying the delimiters for your import maps.
| Hex Code | Character | Hex Code |
Character | Hex Code | Character |
| x09 | TAB | x2A | * | x4A | @ |
| x0A | LF | x2B | + | x5B | [ |
| x0D | CR | x2C | , | x5C | \ |
| x21 | ! | x2D | - | x5D | ] |
| x22 | " | x2E | . | x5E | ^ |
| x23 | # | x2F | / | x5F | _ |
| x24 | $ | x3A | : | x60 | ` |
| x25 | % | x3B | ; | x7B | { |
| x26 | & | x3C | < | x7C | | |
| x27 | ' | x3D | = | x7D | } |
| x28 | ( | x3E | > | x7E | ~ |
| x29 | ) | x3F | ? | | |
Import Options
Clicking this button displays the control
and preference switches you may choose from
to govern how your import map will function.
Specifically, default settings and pre-filled
options. Press F1 on any field to obtain
greater detail on each individual field.
Date Format Options
The dates in the imported files can be represented in a
number of ways. Selecting this control opens the
Import Date Options form where you can choose from a
selection of date formats. Dates are converted into the
Collect! internal date format when importing.
Import
Selecting this takes you to the Import menu form.
Export
Selecting this takes you to the Export menu form.
Delete
Select this to delete the highlighted item from
the database.
This button is visible only on the list of all
File Format Specifications.
Edit
Select this to open and modify the highlighted item.
This button is visible only on the list of all
File Format Specifications.
New
Select this to open a new blank form where
you can create a new File Format Specification.
\this button is visible only on the list of all
File Format Specifications.
Help
Press this button for help on the File Format Specification
form and links to related topics.
Cancel
Select this button to ignore any changes you may
have made and then return to the previous form.
OK
Selecting this button will save any data you have
entered and return you to the previous form.
<<
Selecting this button will take you back
to another record.
>>
Selecting this button will take you forward
to another record.
Records
The list of Import Record Definitions defines which
record types are to be imported. The Collect! Inter Office
file formats work with multiple record types in one file,
but files from other sources will have only one record type.
When you transfer more than one record type, each record
type requires a unique identifier. This allows the import to
know which record a particular line in the file refers to.
Order Of Record Types
The order of the record types is also important. Account
record types should always come before the Contact,
Transaction and Note record types. This is because Import
scans each line of the file, compares the record type
identifier, and creates the record after reading the fields
and checking for duplicates. Since, for example,
Transactions belong to an Account record, you need to
save the Account record before you attempt to save
Transactions belonging to that Account.
| 
Was this page helpful? Do you have any comments on this document? Can we make it better? If so how may we improve this page.
Please click this link to send us your comments: helpinfo@collect.org